Rate Limiting / Throttling Algorithm
Pattern Overview
Leaky Bucket Algorithm
Leaky bucket (closely related to token bucket) is an algorithm that provides a simple, intuitive approach to rate limiting via a queue which you can think of as a bucket holding the requests. When a request is registered, it is appended to the end of the queue. At a regular interval, the first item on the queue is processed. This is also known as a first in first out (FIFO) queue. If the queue is full, then additional requests are discarded (or leaked).
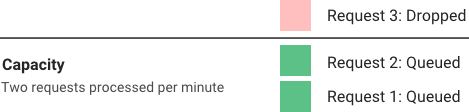
The advantage of this algorithm is that it smooths out bursts of requests and processes them at an approximately average rate. It’s also easy to implement on a single server or load balancer, and is memory efficient for each user given the limited queue size.
However, a burst of traffic can fill up the queue with old requests and starve more recent requests from being processed. It also provides no guarantee that requests get processed in a fixed amount of time. Additionally, if you load balance servers for fault tolerance or increased throughput, you must use a policy to coordinate and enforce the limit between them. We will come back to the challenges of distributed environments later.
Fixed Window
In a fixed window algorithm, a window size of n seconds (typically using human-friendly values, such as 60 or 3600 seconds) is used to track the rate. Each incoming request increments the counter for the window. If the counter exceeds a threshold, the request is discarded. The windows are typically defined by the floor of the current timestamp, so 12:00:03 with a 60-second window length, would be in the 12:00:00 window.
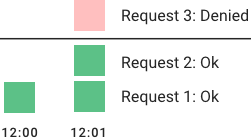
The advantage of this algorithm is that it ensures more recent requests gets processed without being starved by old requests. However, a single burst of traffic that occurs near the boundary of a window can result in twice the rate of requests being processed, because it will allow requests for both the current and next windows within a short time. Additionally, if many consumers wait for a reset window, for example at the top of the hour, then they may stampede your API at the same time.
Sliding Window
This is a hybrid approach that combines the low processing cost of the fixed window algorithm, and the improved boundary conditions of the sliding log. Like the fixed window algorithm, we track a counter for each fixed window. Next, we account for a weighted value of the previous window’s request rate based on the current timestamp to smooth out bursts of traffic. For example, if the current window is 25% through, then we weight the previous window’s count by 75%. The relatively small number of data points needed to track per key allows us to scale and distribute across large clusters.
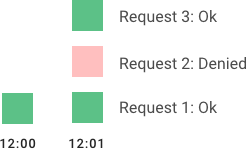
We recommend the sliding window approach because it gives the flexibility to scale rate limiting with good performance. The rate windows are an intuitive ways to present rate limit data to API consumers. It also avoids the starvation problem of leaky bucket, and the bursting problems of fixed window implementations.
Reference Material
Kong Guide to Rate Limiting Algorithms
Figma Guide to Rate Limiting Algorithms
When to use this pattern
- To ensure that the system continues to meet service level agreements.
- To prevent a single tenant from monopolizing the resources provided by an application.
- To handle bursts in activity.
- To help cost-optimize a system by limiting the maximum resource levels needed to keep it functioning.
Design Considerations
General
Scalable (Low Memory Footprint)
- All implementations should have low memory footprint as much as possible.
Avoid Brusts
- We should uniformly spread the load against time window.
Control Over Accuracy
- Consumer should have control over accuracy of system, means we should be able to accurately limit based on no of seconds
Flexible
- Overall our rate limiter library should be able to support multiple strategies and multiple backend drivers.
Telemetry
- We should be able to acquire stats count for how much limits are remaining in each strategy.
Logging
- We should support multiple logging drivers for our library.
API Design
- We should have a main RateLimiter class with configurable constraints
- Time Window should be configurable on main rate Limiter.
- Max Threshold Should be configurable on main rate limiter.
- Hit Method should be available on main rate limiter.
- Check method on main instance should be present for clients.
- Access (combining both hit and check) should be present for clients.
- We should be able to pass rate limiting strategy to main rate limiter with its own options
- We should be able to pass storage adapters to rate limiter
- We should be able to pass logging adapters to rate limiter
Real World References
Possible Future Improvements
- Implement as a microservice (Reference: gubernator)
- Implement as an express middleware.(Reference:ratelimit.js )
- Implement as axios rate limiting middleware (Reference: axios-rate-limit )