Architecture
At Carbonteq, we have found a great amalgam of architectural patterns and principles, we intend these to be basic building blocks of reasoning which can be used to deduce surprising or difficult things.
You have already gone through SOLID by now, I presume. Another integral part of our architecture is the clean architecture. Note that we don't follow the pattern itself dogmatically, but rather use the principles that guide it.
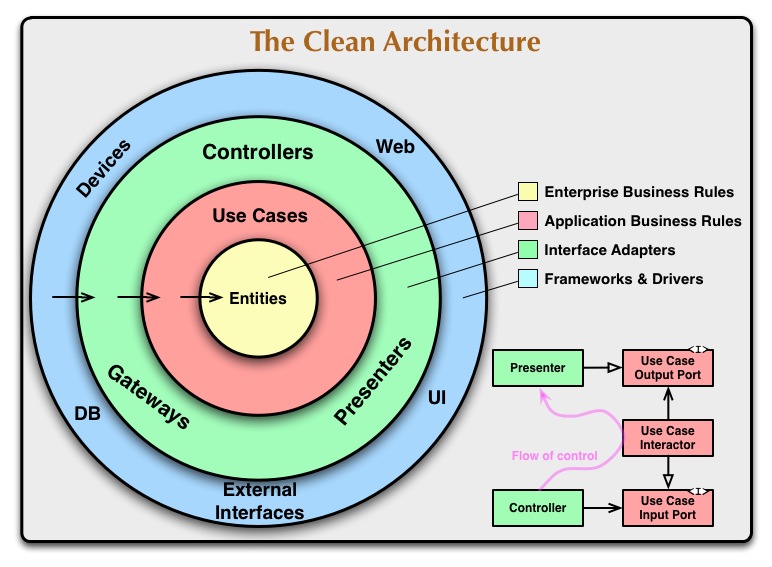
The crux of the hexagonal architecture and the clean architecture lies in two main concepts: layers, and ports and adapters.
- Objects in a layer can "talk" to the objects in the layer above or below only, and none other.
- The outer layer depends on the inner one, and never the other way around.
- Ports specify the abstract methods and interfaces (like for repositories), implemented in some other place by adapters, allowing us to inverse the direction of dependencies and ensuring the domain logic does not depend on implementation details for things like persistence and data transport mechanisms.
These two help the developer outline and enforce our principles cleanly (or as close to it as we can get). I won't go into the explanation of this architecture, as the linked resources do a far better job of that.
All established patterns we try to follow
- Hexagonal (Ports and Adapters) Architecture
- Clean Architecture
- Onion Architecture
- SOLID Principles
- Software Design Patterns
Project Organization
Looking at a given project in Carbonteq, you'll typically see the backend divided into four to five directories: domain, app/application, infra/infrastructure, and web/HTTP. This section provides a brief explanation of the directory structure and how it corresponds to the layered architecture outlined above. Any terms that require clarification can probably be found in the glossary section below.
Domain Layer
Domain corresponds to the innermost domain layer and contains applications business rules, and is usually achieved using . Entities, repositories, value objects, domain exceptions and domain services are placed here, organized by aggregates.
Application Layer
App deals with the objects in the application layer, namely the application services, application results and DTOs. Transaction management, execution of work commands, handling of domain events and business process flows are all codified here.
Infrastructure (Not A Layer)
Then comes infrastructure, where we provide the adapters of the ports defined in the domain and application layers, the infrastructure services, and the application config. Some common adapters you will implement in almost every project will be the database repositories and application logger. It does not correspond to any layer, but rather is present for organizing all the adapters in one common place.
Presentation/Interface Layer
Finally, we come to the outermost layer. It usually contains only the HTTP/web module (although depending on your application, you may also provide a CLI module). The only job of this layer is to act as a kind of middleman between the application layer and the user, a thin wrapper abstracting away the data transport details. The application services don't really care where the data is coming from, whether from a terminal, a file, an RPC call or over HTTP. That's not their concern. As long as data is reaching them in a valid form (courtesy of DTOs), they'll work with it happily and return the appropriate application result. The wrapping layer (web or CLI) will then convert the application result to the appropriate form based on the underlying transport mechanism, and send it to the client. E.g. if you get an Ok Result from the app service in your API's http controller, you'll unwrap the result data and maybe serialize it to JSON before sending it to the client, or if it's an Error Result, you'll return a 4xx/5xx response.
Resources
Glossary
Application Service
The application service is what presents an input for a use-case. It calls off to the domain for execution, calls any other services (like notifications) and returns. Application Services will typically use both Domain Services and Repositories to deal with external requests.
Data Transfer Object
A Data Transfer Object (DTO) is a data container which is used to transport data between layers and tiers. It mainly contains of attributes. DTOs are anemic in general and do not contain any business logic.
- DTOs should be data-oriented, not object-oriented. Its properties should be mostly primitives. We are not modeling anything here, just sending flat data around.
- If DTO decorators for validation/documentation are not used, DTO can be just an interface instead of class + interface.
tip
Validation At Runtime
Data should not be trusted. There are a lot of cases when invalid data may end up in a domain. For example, if data comes from external API, database, or if it's just a programmer error.
Things that can't be validated at compile time (like user input) are validated at runtime.
First line of defense is validation of user input DTOs. Request/Response DTO classes may be a good place to use validation and sanitization decorators like class-validator and class-sanitizer (make sure that all validation errors are gathered first and only then return them to the user, this is called Notification pattern. Class-validator does this by default).
Aggregate
An aggregate is a set of domain objects, usually called Entities and Value Objects, that are considered as a single item inside our bounded context. One of the entities that make up the Aggregate is called the Aggregate Root or Root Entity. This entity owns all the others inside the aggregate. Other objects interact with the objects within the aggregate via the aggregate root, and never directly. A set of consistency rules (invariants) applies within the Aggregate’s boundaries.
Domain Events
Domain Event indicates that something happened in a domain that you want other parts of the same domain (in-process) to be aware of. Domain events are just messages pushed to an in-memory Domain Event dispatcher.
An important benefit of domain event is side effects can be expressed explicitly, alternate is you would code something close to the code where event is happening usually violating the single responsibility principle
Domain Events may be useful for creating an audit log to track all changes to important entities by saving each event to the database. Read more on why audit logs may be useful: Why soft deletes are evil and what to do instead . All changes caused by Domain Events across multiple aggregates in a single process can be saved in a single database transaction. This approach ensures consistency and integrity of your data.
Further Reading Microsoft Domain Events: Design and implementation
Integration Event
Out-of-process communications (calling microservices, external apis) are called Integration Events. If sending a Domain Event to external process is needed then domain event handler should send an Integration Event.
Integration Events usually should be published only after all Domain Events finished executing and saving all changes to the database.
To handle integration events in microservices you may need an external message broker / event bus like RabbitMQ or Kafka together with patterns like Transactional outbox, Change Data Capture, Sagas or a Process Manager to maintain eventual consistency.
note
Domain events versus integration events
Semantically, domain and integration events are the same thing: notifications about something that just happened. However, their implementation must be different. Domain events are just messages pushed to a domain event dispatcher, which could be implemented as an in-memory mediator based on an IoC container or any other method.
On the other hand, the purpose of integration events is to propagate committed transactions and updates to additional subsystems, whether they are other microservices, Bounded Contexts or even external applications. Hence, they should occur only if the entity is successfully persisted, otherwise it's as if the entire operation never happened.
Read More:
Domain Service
- Domain Service is a specific type of domain layer class that is used to execute domain logic that relies on two or more Entities.
- Domain Services are used when putting the logic on a particular Entity would break encapsulation and require the Entity to know about things it really shouldn't be concerned with.
- Domain services are very granular, while application services are a facade purposed with providing an API.
- Domain services operate only on types belonging to the Domain. They contain meaningful concepts that can be found within the Ubiquitous Language. They hold operations that don't fit well into Value Objects or Entities.
Entity
- Entity encapsulate most of the domain business logic, avoid putting business logic in services
- Domain objects characterized by having an identity that’s not tied to their attribute values. All attributes in an entity can change, and it’s still the same entity. Conversely, two entities might be equivalent in all their attributes, but will still be distinct.
- Complex entities usually contains other value objects
- API should be created to accommodate business logic not database schema, as a result id is generated within code not in database buts it's not limited to this
- Entities should protect their invariants
- Must be consistent on creation, validate entities on creation and throw error on failure.
- Try to update state using methods and execute invariant validation on each update if needed.
- For optional properties and complex setups Fluent Interfaces, Factor Method and Builder Pattern can be used
Repository
"A mechanism for encapsulating storage, retrieval, and search behavior which emulates a collection of objects."
Repositories are abstractions over collections of entities that can live anywhere, they protect us from taking a data-centric view of our code. They allow us to persist and retrieve aggregates without dealing directly with the underlying persistence. It is however important for developers to at least be aware of the underlying implementations so as not to abuse the repository from a performance or scoping way. What is important is that the repository handles mapping however the data is persisted into a fully hydrated and consistent aggregate.
Value Object
"A Value Object, or simply a Value, models an immutable conceptual whole. Within the model the Value is just that, a value. Unlike an Entity, it does not have a unique identity, and equivalence is determined by comparing the attributes encapsulated by the Value type. Furthermore, a Value Object is not a thing but is often used to describe, quantify, or measure an Entity." - Vaughn Vernon
- Can be used as an attribute of entities and other value objects.
- Explicitly defines and enforces important constraints (invariants).
- It isn’t just a data structure that holds values. It can also encapsulate logic associated with the concept it represents.
Try to replace primitives with value objects
Significant business concepts can be expressed using specific types and classes. Value Objects can be used instead primitives to avoid primitives obsession. So, for example, email of type string:
email: string;
could be represented as a Value Object instead:
email: Email;
Now the only way to make an email is to create a new instance of Email class first, this ensures it will be validated on creation and a wrong value won't get into Entities. :::
Domain Invariants
Domain invariants are the policies and conditions that are always met for the Domain in particular context. Invariants determine what is possible or what is prohibited in the context.
Invariants enforcement is the responsibility of domain objects (especially of the entities and aggregate roots).
There are a certain number of invariants for an object that should always be true. For example:
- When sending money, amount must always be a positive integer, and there always must be a receiver credit card number in a correct format;
- Client cannot purchase a product that is out of stock;
- Client's wallet cannot have less than 0 balance; etc.
If the business has some rules similar to described above, the domain object should not be able to exist without following those rules.
Read more:
- Design validations in the domain model layer
- Why Domain Invariants are critical to build good software?
Guarding vs Validating
You may have noticed that we do validation in two places:
- First when user input is sent to our application. Usually in DTOs.
- Second time in domain objects (Aggregate, Entity and ValueObject).
So, why are we validating things twice? Let's call a second validation "guarding", and distinguish between guarding and validating:
Guarding is a failsafe mechanism. Domain layer views it as invariants to comply with always-valid domain model. Validation is a filtration mechanism. Outside layers view them as input validation rules. This difference leads to different treatment of violations of these business rules. An invariant violation in the domain model is an exceptional situation and should be met with throwing an exception. On the other hand, there’s nothing exceptional in external input being incorrect.
The input coming from the outside world should be filtered out before passing it further to the domain model. It’s the first line of defense against data inconsistency. At this stage, any incorrect data is denied with corresponding error messages. Once the filtration has confirmed that the incoming data is valid it is passed to a domain. When the data enters the always-valid domain boundary, it is assumed to be valid and any violation of this assumption means that you’ve introduced a bug. Guards help to reveal those bugs. They are the failsafe mechanism, the last line of defense that ensures data in the always-valid boundary is indeed valid. Unlike validations, guards throw exceptions; they comply with the Fail Fast principle.
Domain classes should always guard themselves against becoming invalid.
For preventing null/undefined values, empty objects and arrays, incorrect input length etc. a library of guards can be created.
info
Coming Soon
- Domain Errors
- Adapters
- Validation at compile time
- Using Libraries inside application core
- Custom utility types :::